In this project, we are investigating the internal representations of a shallow CNN trained to detect electrographic seizures. We are specifically interested in understanding how the model makes decisions at the single neuron and/or ensemble level and going beyond standard input attribution methods.
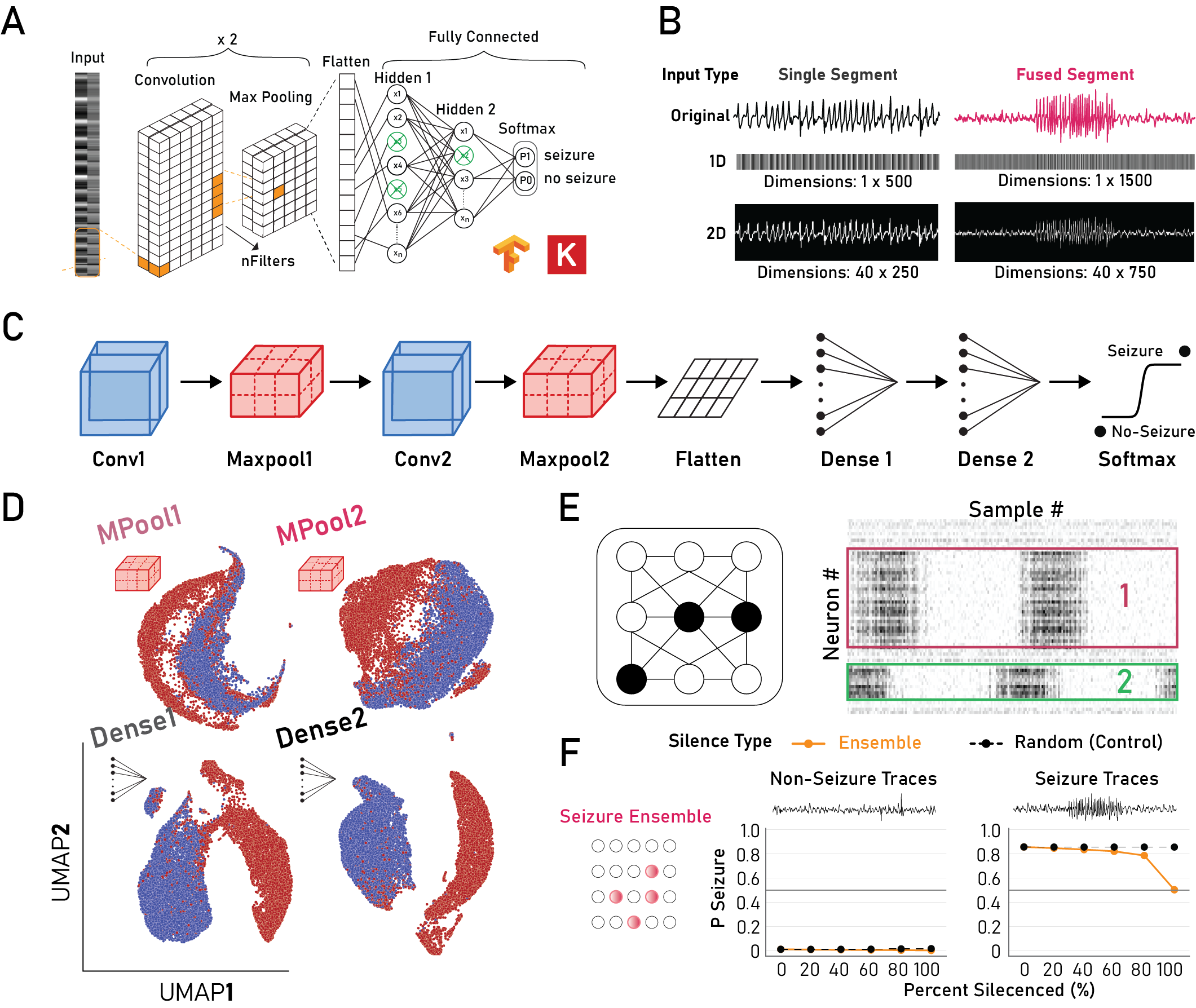
Figure: A) Model architecture, B) Input types, C) Model schematic, D) Separation of activations using PCA (nPCs=100) with UMAP, E) Ensemble identification strategy schematic, F) Silencing of seizure ensembles reduces model prediction to chance only for seizure traces.
Some early findings include:
1) Separation of seizure and non-seizure traces begins from the first convolutional layer.
2) Intermediate layers form sparse representations with high-redundancy across layers.
3) Silencing of class-specific ensembles predictably alters model decision outcomes.
Coming soon
Stay tuned for the arXiv paper where we will be exploring human interpretable features to explain model decisions based on inputs, dense neuron clusters, and more.
]]>