
Interpreting CNN Decision-Making in EEG Seizure Detection
Deep learning models can achieve strong performance on EEG and LFP classification tasks, but understanding how they arrive at their decisions remains challenging. This project investigates the internal representations and decision-making processes of a shallow convolutional neural network trained to detect electrographic seizures.
Rather than relying only on input attribution, I examined how information is represented across layers, how class-specific neural ensembles contribute to model predictions, and how internal computations relate to human-interpretable electrophysiological features.
Motivation
Automated seizure detection has the potential to accelerate neuroscience research and support clinical workflows. However, high-performing deep learning models remain difficult to trust when their decision-making process is opaque.
The central question in this project is:
Can we understand how a seizure-classification CNN internally represents electrographic activity and uses those representations to make decisions?
Approach
After training shallow CNN models on large-scale electrographic seizure recordings, I analyzed the network at multiple levels to understand how representations emerge and support classification.
The project combines:
- Layer-wise activation analysis
- PCA, UMAP, and representation-space analysis
- Linear decoding from internal activations
- Identification of dense-layer neural ensembles
- Causal silencing and activation experiments
- Signal filtering and perturbation studies
- Human-interpretable feature analysis
- SHAP-based model explanation
Key Findings
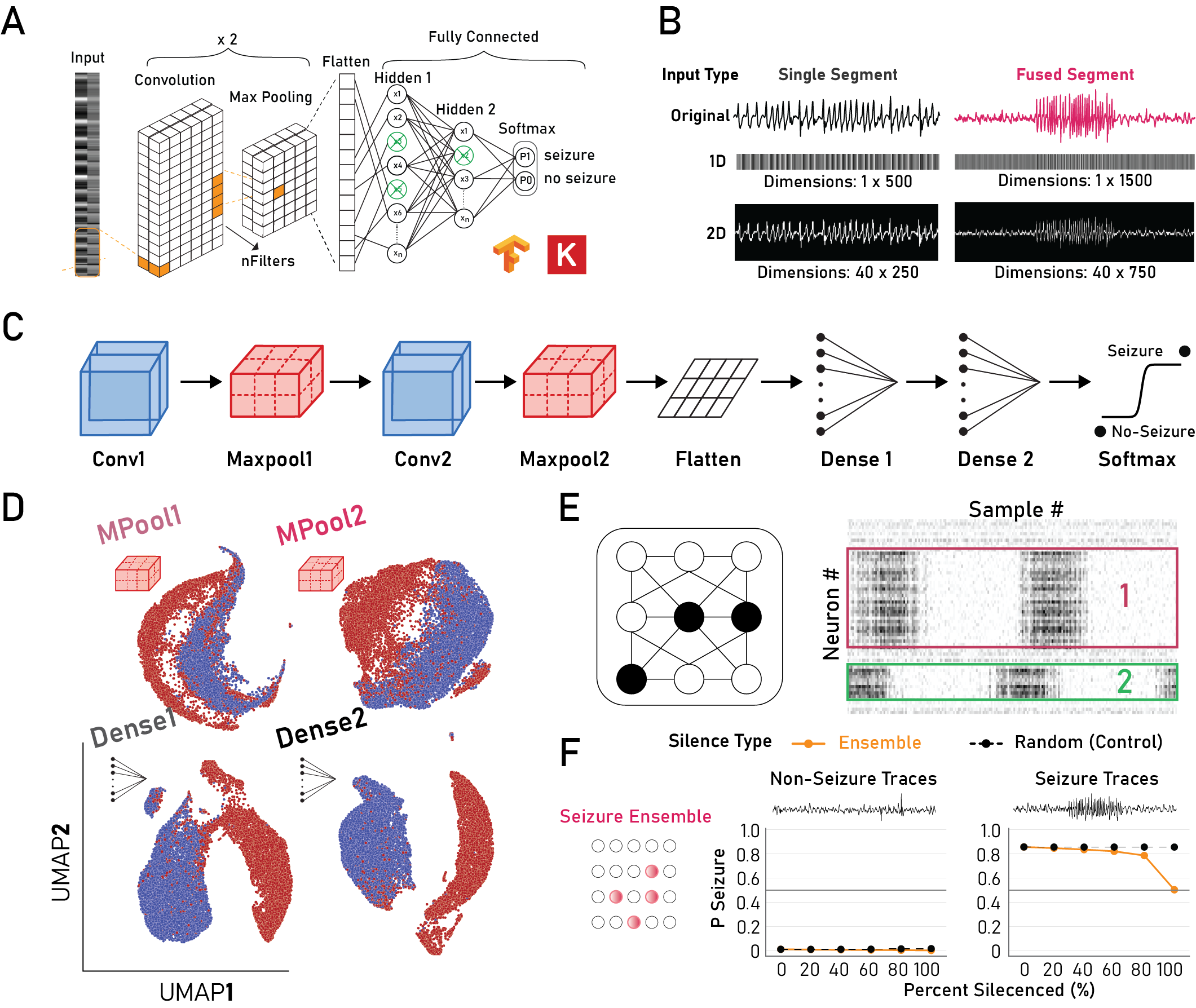
Figure: A) Model architecture, B) Input types, C) Model schematic, D) Separation of activations using PCA (nPCs=100) with UMAP, E) Ensemble identification strategy schematic, F) Silencing of seizure ensembles reduces model prediction to chance only for seizure traces.
Emergence of class-specific representations
Representations become progressively more separable across network depth. While seizure-related information is already present in early convolutional layers, deeper layers transform these features into increasingly compact and linearly separable representations.
Causal influence on model decisions
Manipulating class-specific ensembles directly alters model predictions. Silencing seizure-related ensembles reduces seizure probability, while activating them increases seizure probability. Similar bidirectional effects are observed for non-seizure ensembles.
These experiments move beyond correlation and provide evidence that specific internal representations causally contribute to model behavior.
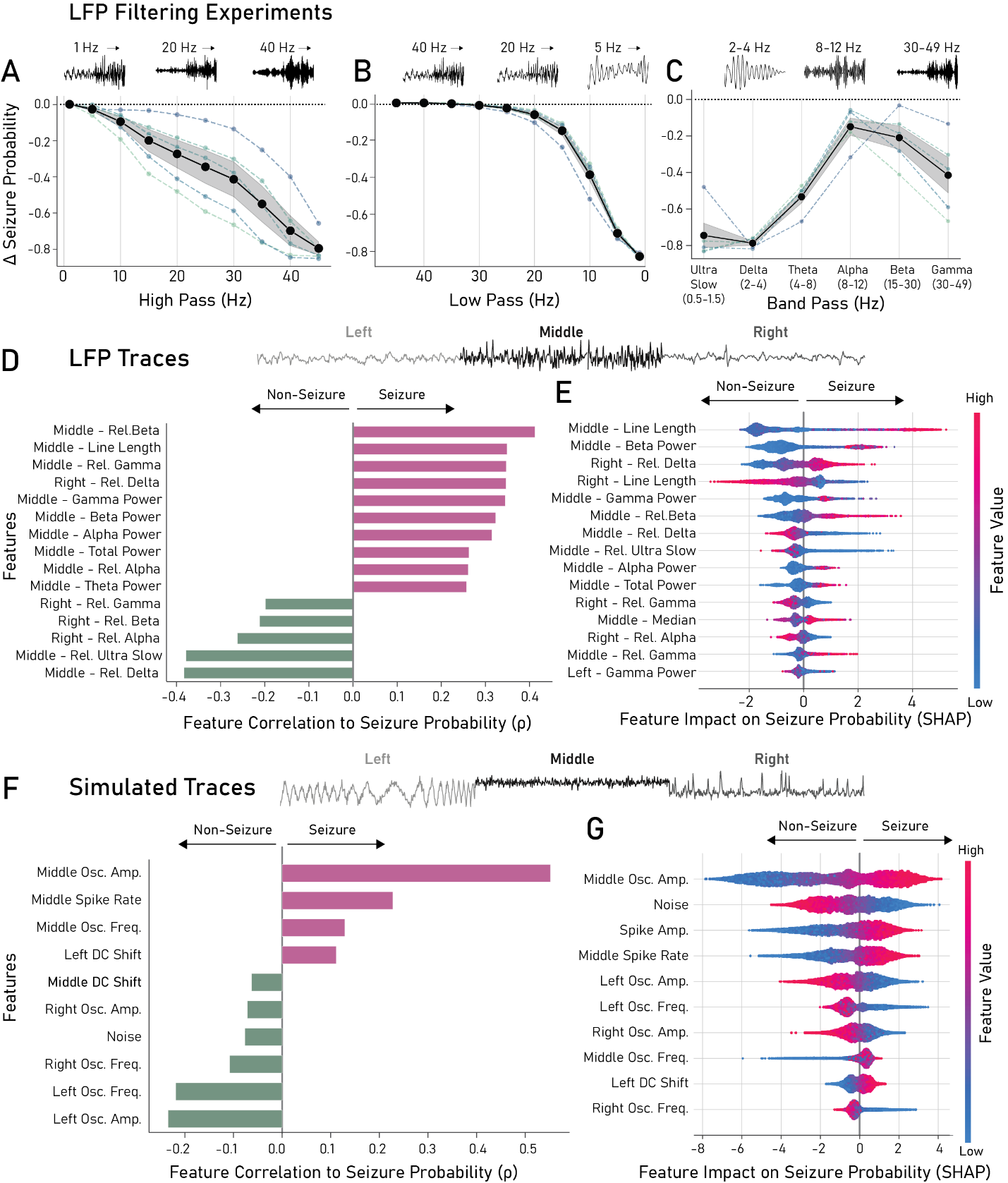
Figure: A-C) Frequency filtering experiments reveal the spectral components most important for seizure classification. D-E) Correlation and SHAP analyses link model predictions to human-interpretable electrophysiological features. F-G) Synthetic signal experiments identify waveform characteristics that drive seizure probability and model behavior.
Human-interpretable features
Model decisions are strongly influenced by structured oscillatory activity and spike-like waveform features. Feature analysis suggests that alpha/beta-range activity, oscillation amplitude, line length, and relative changes between central and peripheral segments contribute substantially to classification decisions.
This provides a bridge between internal model representations and electrophysiological features that are meaningful to neuroscientists and clinicians.
Why This Matters
This project reflects a broader interest in understanding how learned systems represent information, make decisions, and fail. Although the model studied here is a relatively small CNN, many of the underlying questions are similar to those being asked about modern AI systems:
- How do internal representations emerge?
- How are representations transformed across layers?
- Which internal components are causally responsible for behavior?
- Can model decisions be connected to interpretable features?
Understanding these mechanisms may help improve trust, robustness, interpretability, and ultimately the deployment of machine learning systems in high-stakes domains such as healthcare.